 Roy Zanbel
Roy Zanbel

AI-generated voices have crossed a critical threshold. What once sounded robotic and gimmicky now passes as human, with emotion, nuance, and intent. The rapid evolution of AI voice synthesis has opened the door to remarkable innovation. But it has also created a new class of security vulnerabilities.
In this post, we explore how advances in voice cloning and real-time synthesis are enabling new forms of deception and why current detection and defense strategies are struggling to keep up. In one real-world case, an attacker used a cloned voice to impersonate a company’s CFO during a phone call, successfully tricking an employee into initiating a six-figure transfer. Such incidents are no longer rare anomalies — they’re a glimpse into what’s quickly becoming the norm and why current detection and defense strategies are struggling to keep up.
From Robotic to Real: The Evolution of AI Voice
AI voice synthesis has improved at a staggering pace. Recent breakthroughs have solved three long-standing challenges:
- Realism & Emotion: New models replicate subtle speech characteristics like pacing, intonation, and mood.
- Rapid Voice Cloning: Zero-shot and few-shot techniques allow cloning of a voice from just seconds of audio.
- Low-Latency Synthesis: Voice conversion and TTS systems now work in real-time with latency under 75ms.
Leading companies like ElevenLabs, Sesame, and Canopy Labs have pioneered commercial-grade solutions indistinguishable from real voices. Open-source tools have made high-quality cloning widely accessible. Underlying techniques like neural TTS, flow matching, and diffusion-based models allow these systems to adapt quickly to any speaker, tone, or context.
The Deepfake Attack Pipeline: Anatomy of a Modern Voice Exploit
The emergence of accessible voice AI has led attackers to refine a multi-stage pipeline for executing deepfake audio attacks.
It begins with data collection. Voice samples are pulled from public sources — interviews on YouTube, podcast appearances, or leaked voice messages. These recordings form the foundation for cloning, often requiring just seconds of clean audio to begin replication.
Next comes the synthesis phase. Attackers leverage a range of technologies to weaponize this voice data. Text-to-speech (TTS) models can reproduce the exact tone and cadence of a target, while real-time voice conversion tools allow an attacker to speak in another person’s voice during live interactions. Audio editing tools are used to splice, reword, or fabricate statements in recorded audio. More sophisticated threats involve AI-generated voice agents — entirely synthetic personas capable of conducting full conversations, often used in robocalls and large-scale fraud campaigns.
Finally, there’s the delivery mechanism. These synthetic voices are injected into communication channels such as social engineering calls, deepfake videos, or robocall campaigns. The result is fast, low-cost, scalable impersonation that doesn’t require any live human participation. Attackers can convincingly pose as CEOs, law enforcement officials, or trusted employees, executing deception at scale and speed.
Deepfake Voice Attack Techniques and Intent
Deepfake audio attacks are becoming more sophisticated by the day, drawing from a growing arsenal of tools and techniques. These aren’t theoretical threats — they’re already being used in the wild. Here are four core types of deepfake voice attacks increasingly seen in practice:
-
Text-to-Speech (TTS) Playback: Attackers use TTS models to generate entirely synthetic recordings that mimic a real person reading scripted content, ranging from emails and invoices to directives or legal statements.
-
Voice Conversion (VC): In real-time calls or interactions, attackers apply voice conversion to transform their own voice into that of a target, enabling seamless live impersonation during phishing or social engineering attacks.
-
Editing Attacks: Instead of generating new content, attackers manipulate authentic voice recordings — adding, replacing, or rearranging words to fabricate new messages or mislead listeners. This is particularly dangerous in legal or journalistic contexts.
-
AI Voice Agents: By combining cloned voices with low-latency, autonomous response systems, attackers can deploy fully synthetic voice agents that carry out conversations in real time, massively scaling impersonation without human intervention.
These techniques are not only becoming easier to access — they’re also becoming harder to detect. Especially concerning is the emergence of nation-state actors leveraging customized voice models and advanced synthesis pipelines. Their tactics can bypass many of today’s detection systems, raising the stakes for both commercial and government entities facing high-stakes impersonation threats.
In one real-world example that illustrates just how advanced these threats have become, a multinational firm was targeted with a deepfake voice impersonation attack. The scammers used AI-generated audio to convincingly mimic a senior executive during a phone call, leading to a $25M financial loss. As Rob Greig, Chief Information Officer at Arup, described:
This attack used psychology and sophisticated deepfake technology to gain the employee’s confidence. It’s an example of how cybercrime is evolving.
— Rob Greig, Chief Information Officer at Arup
This kind of attack blends voice cloning, real-time interaction, and social engineering, making it difficult to detect and nearly impossible for the average employee to distinguish from a legitimate call.
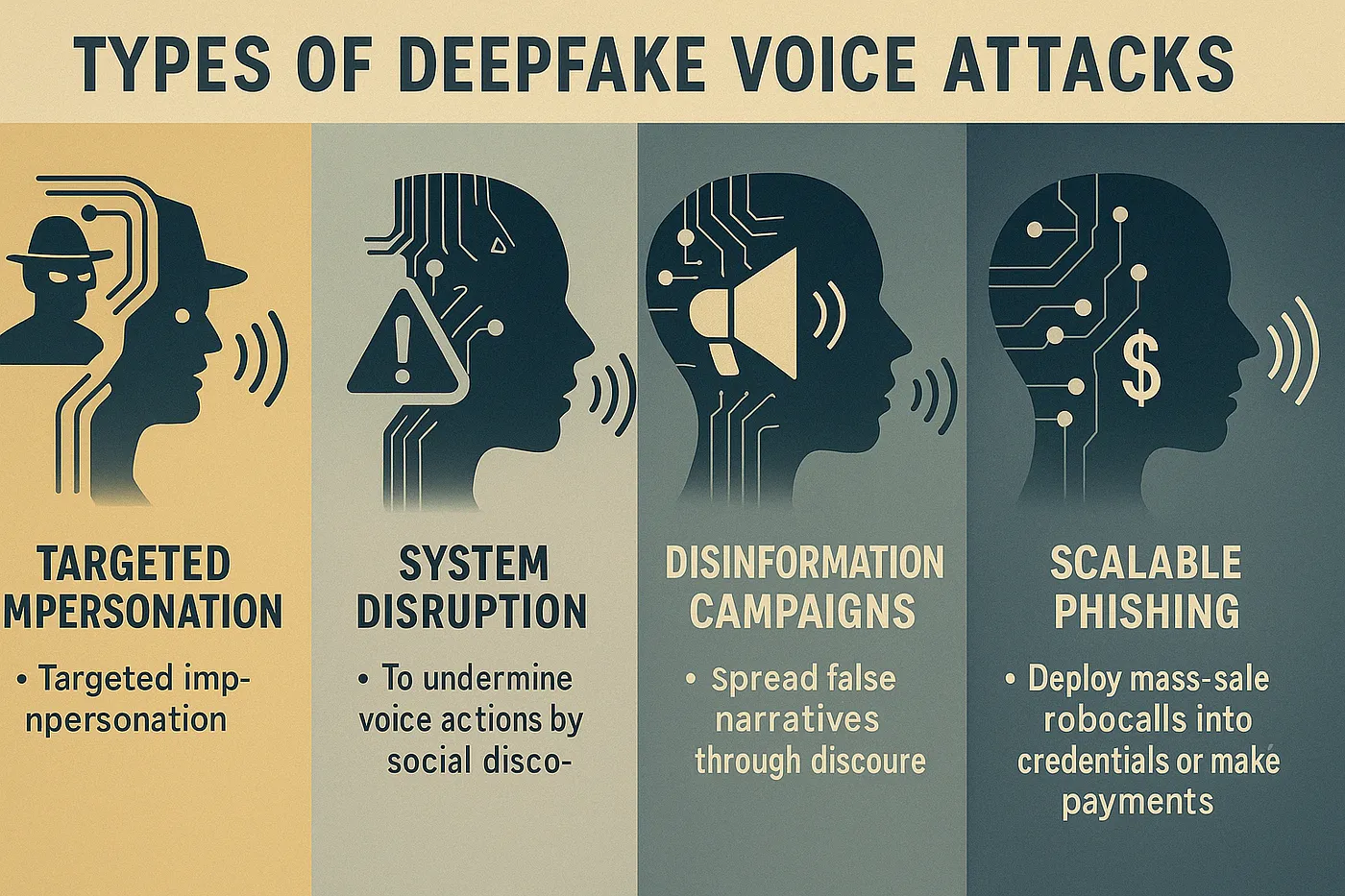
Types of Deepfake Voice Attacks
While deepfake techniques describe how these attacks are carried out, the intent behind them can vary widely, and understanding these motives is key to assessing their risk. Here are the primary categories of attack intent observed across real-world incidents:
-
Targeted Impersonation: These attacks involve mimicking specific individuals, like executives, law enforcement, or public figures, to commit fraud, extract sensitive information, or manipulate outcomes in high-trust environments.
-
System Disruption: Adversaries may seek to undermine voice authentication systems or cause system failures by triggering false positives or rejections. This form of attack can halt operations or force reliance on insecure fallback procedures.
-
Disinformation Campaigns: Synthetic speech is used to spread false narratives through fake audio clips or manipulated voice messages, often targeting political or social discourse.
-
Scalable Phishing: By combining deepfake voices with automation, attackers can deploy mass-scale robocalls, impersonating trusted entities to trick victims into giving up credentials or making payments.
As voice becomes a trusted layer in identity and interaction, each of these intents can have outsized consequences. Systems that rely on voice as a unique biometric signal must evolve to understand and respond to these varied threat models.
The Detection Dilemma
Despite significant progress, detecting synthetic speech remains an arms race between generative capabilities and security countermeasures. Techniques like acoustic and spectrogram analysis help scan for anomalies in tone, pitch, and frequency, while AI classifiers are trained to detect subtle patterns unique to synthetic audio. In parallel, behavioral cues such as unnatural pauses, robotic pacing, or missing emotional depth can sometimes reveal inauthentic speech.
Still, detection is far from perfect. One of the biggest hurdles is the diversity of underlying models. With GANs, VAEs, diffusion techniques, and flow matching all producing different types of output, it becomes increasingly difficult to train detectors that generalize well. These models evolve rapidly, making detection tools obsolete within months. Complicating matters, synthetic voice systems are often fine-tuned to individuals, meaning a single voice identity could have multiple distinct AI-generated versions.
All of this leads to two central problems: general-purpose detection tends to be unreliable, and the risk of false positives can have serious operational and legal consequences. As the tools for creating synthetic voices become more advanced and accessible, the challenge of keeping detection accurate and up-to-date grows exponentially.
Why Traditional Security Isn’t Enough
Most voice protection today focuses on post-factum detection, catching fake audio after it’s been used. But this is like catching a phishing email after the wire transfer has gone through.
What’s needed is a proactive voice security stack capable of:
- Preventing unauthorized cloning through watermarking and voice biometrics protection.
- Hardening AI models to resist adversarial audio inputs.
- Real-time anomaly monitoring across conversational systems.
A New Cybersecurity Frontier
Key Takeaways
- Deepfake voice attacks are real and escalating, driven by rapid innovation in AI voice synthesis.
- Detection alone isn’t enough — defenses must evolve to include proactive, model-level protections.
- Understanding the techniques and intent behind these attacks is critical to designing resilient systems.
What Organizations Can Do Today
- Audit your exposure: Understand how much voice data is publicly available about your executives or employees.
- Implement layered authentication: Don’t rely on voice alone, combine with behavioral and contextual signals.
- Monitor and log voice interactions: Use anomaly detection to flag unusual usage patterns.
- Explore model-level security: Include voice AI in broader AI governance and adversarial robustness planning.
Voice is becoming the next battleground in cybersecurity — just like email in the era of phishing or endpoints in the era of ransomware.
The question is no longer whether synthetic speech is a threat; it’s how soon enterprises and governments will adapt. Defenses must evolve beyond detection, toward resilient design, robust AI models, and secure-by-default voice infrastructure.
Because when anyone can sound like anyone, authenticity becomes the ultimate vulnerability.