 Roy Zanbel
Roy Zanbel

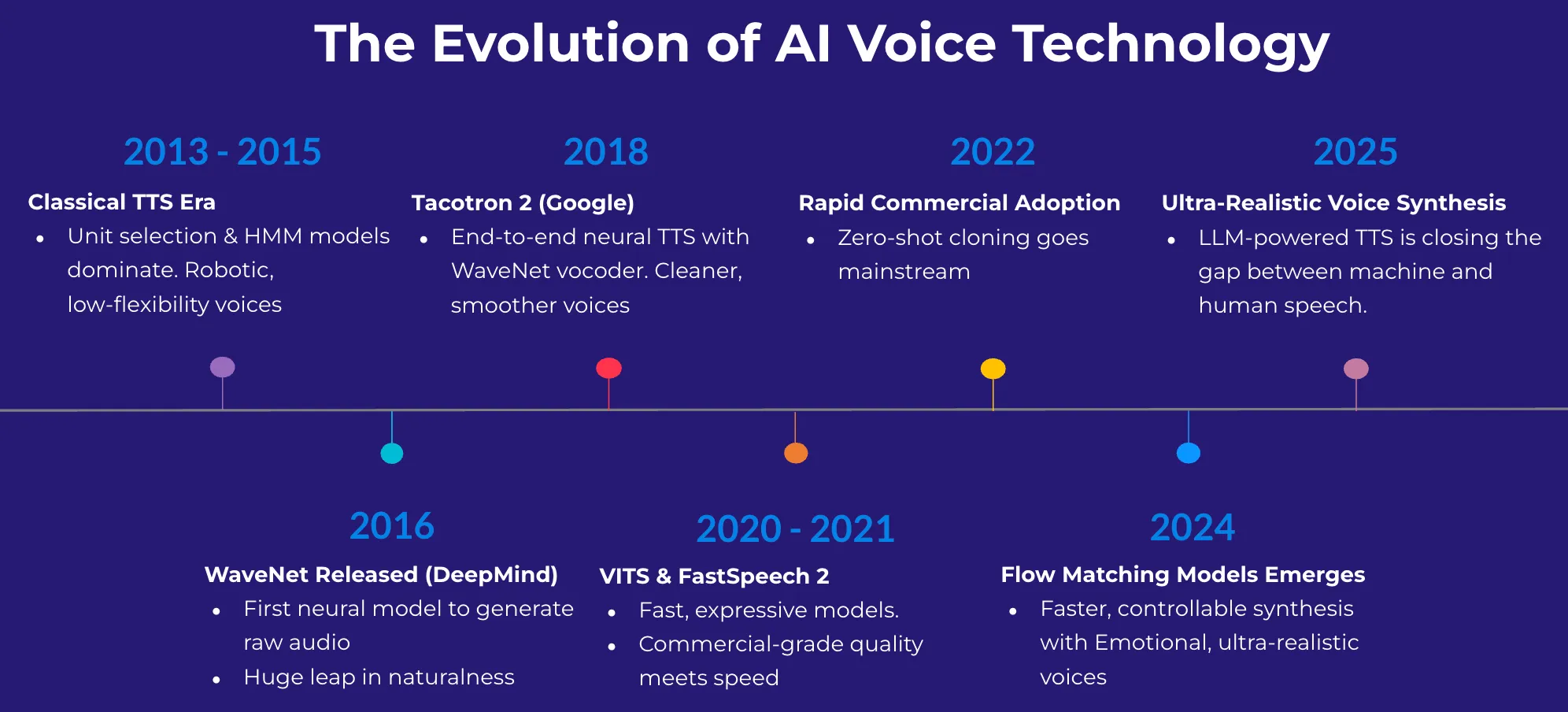
Not long ago, synthetic voices were easy to detect — flat, robotic, and unnatural. Today, AI-generated speech is nearly indistinguishable from human voices, capturing nuances like tone, emotion, and speaking style with remarkable precision.
This leap in realism is driven by advances in deep learning and generative models that solve three major challenges:
- Expressive & Realistic Speech: AI voices now capture subtle intonations, pacing, and emotions that make speech feel human.
- Rapid Voice Cloning: Cloning a voice no longer requires hours of data — new models can mimic a speaker in under 10 seconds with minimal input.
- Low-Latency Synthesis: AI-generated speech can now be processed in real-time, enabling seamless, natural conversations with minimal delay.
These breakthroughs have been made possible by novel AI architectures and training techniques that continue to push the boundaries of speech synthesis.
Advancements in AI Voice Technology
Leading companies like ElevenLabs, Sesame, and Canopy Labs have developed state-of-the-art AI voice models that produce speech nearly indistinguishable from real human voices. These systems rely on deep learning approaches such as:
- Neural Text-to-Speech (TTS) Models: Advanced neural networks generate high-fidelity speech from text by modeling the complex relationship between phonetics and acoustic properties.
- Zero-Shot & Few-Shot Voice Cloning: New cloning methods require only a few seconds of audio to capture a speaker’s identity and replicate their voice.
- Flow Matching & Diffusion-Based Models: Techniques like Flow Matching improve voice cloning by using continuous normalizing flows to generate highly detailed speech while maintaining speaker consistency and clarity across variations.
- End-to-End Voice Conversion: AI can now modify a speaker’s voice in real-time, allowing for seamless transformation while preserving natural expressiveness.
In open-source projects, F5-TTS and CosyVoice 2 have made these capabilities even more accessible, enabling researchers and developers to clone voices with minimal computational overhead. Meanwhile, commercial solutions like Cartesia AI have reduced synthesis latency to under 75ms, making real-time AI voice interactions possible.
The Security Challenges of AI-Generated Voices
As AI-generated voices become more realistic, they are also becoming powerful tools for deception and fraud. Cybercriminals and adversarial actors are already exploiting these advancements in multiple ways:
- Impersonation & Fraud: Attackers use AI voice cloning to imitate CEOs and trick employees into transferring money or revealing sensitive information.
- Bypassing Voice Authentication: Banks and enterprises using voice biometrics are increasingly vulnerable to AI-cloned voices that can mimic registered users.
- Adversarial Attacks on AI Speech Models: AI-generated inputs can manipulate speech recognition systems, bypassing authentication mechanisms or degrading system performance.
The growing accessibility of open-source voice cloning models means that anyone with a few minutes of audio and a laptop can create a highly convincing replica of another person’s voice. This reality raises serious security and privacy concerns that must be addressed.
The Growing Challenge of Deepfake Detection
As AI-generated voices become more advanced, deepfake detection is becoming increasingly complex. The challenge isn’t just about identifying whether a voice is real or synthetic — it’s about keeping up with an evolving landscape of models and techniques.
- Diverse Model Architectures: AI voice synthesis isn’t limited to one type of model. Each generation of models — GANs, VAEs, diffusion models, Flow Matching — produces different artifacts, making detection more difficult.
- Adversarial Evolution: As detection methods improve, generative AI models also evolve to evade detection by refining how they replicate speech patterns and remove detectable artifacts.
- Model Proliferation: There is no single standard for AI voice synthesis — multiple companies and open-source projects continuously release new approaches, forcing detection models to adapt at an unprecedented rate.
- Fine-Tuning & Personalization: AI voices can be personalized at an individual level, meaning a single speaker’s synthetic voice may exist in multiple different synthetic forms — making one-size-fits-all detection unreliable.
Deepfake detection has historically struggled to keep up with visual deepfake techniques, and now the same challenge is emerging for AI-generated voices. Traditional detection approaches will likely need to incorporate multi-layered security, including behavioral analysis, AI model hardening, and real-time anomaly detection to remain effective.
Some of the most concerning incidents that we’ve seen have been audio deepfakes. Audio, frankly, is easier to clone. And, you know, for most of us, we’re maybe more likely to be fooled by a reasonably convincing audio of a prominent public figure.
— Dan Weiner, Brennan Center’s Elections & Government Program
Why Traditional Security Measures Are Not Enough
Right now, most efforts to combat AI-generated voice fraud rely on deepfake detection, which identifies AI-generated voices after they have been used maliciously. However, this approach is inherently reactive — by the time a fake voice is detected, the damage may already be done.
This mirrors past cybersecurity challenges. Early email security relied on spam filters and phishing detection, but as attacks evolved, proactive defenses like email authentication and real-time monitoring became essential. The same shift is needed for AI-generated voice security.
The Need for AI Voice Security
As synthetic voices become an integral part of telecommunications, customer service, and security systems, the need for robust voice security measures is clear.
Organizations involved in AI voice security are exploring methods to:
- Prevent unauthorized voice cloning by watermarking or securing biometric data.
- Detect adversarial voice manipulations before they can be exploited.
- Enhance AI model security to prevent voice cloning tools from being misused.
Just as cybersecurity adapted to protect endpoints, emails, and networks, voice security must evolve to safeguard against the next generation of AI-driven threats. Those who address these risks early will be better positioned to navigate the rapidly changing landscape of AI-generated voices.